索引-数据表的“氮气罐”
作为新手小白的你,曾经一定和我一样,在各个地方听到过“索引”的大名。今天我们来根据一个实际的案例,触摸这个晦涩的概念。希望读完这篇文章,你也可以把索引灵活运用在自己的工作学习中。
阅读这篇文章之前,我要抛给你一个问题,并且希望你能带着这个问题去思考如下整篇文章:
为什么要有索引呢?
数据准备
直接来看一个案例:
业务场景
我在做一个公众号的后台服务,整体采用微服务的架构。
其中某个服务包含了一张mysql表,大概有150w条用户数据。我需要设计一个定时任务,每天的某个时间轮询的扫描这张表。表结构大概是这样的:
|
|
可以直接使用可视化工具导入上面的sql来建立表格。
我使用的是 Navicat 16。建表成功之后,可以很方便的使用Navicat 16 的生成数据功能,生成100w条测试数据:
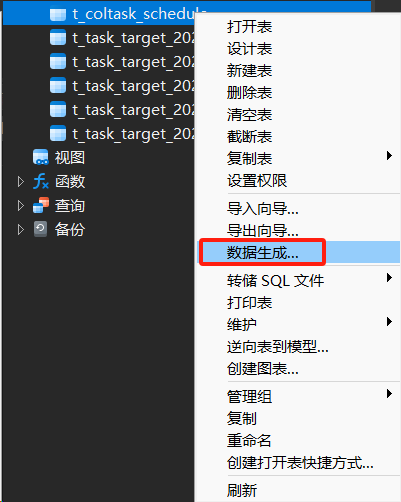
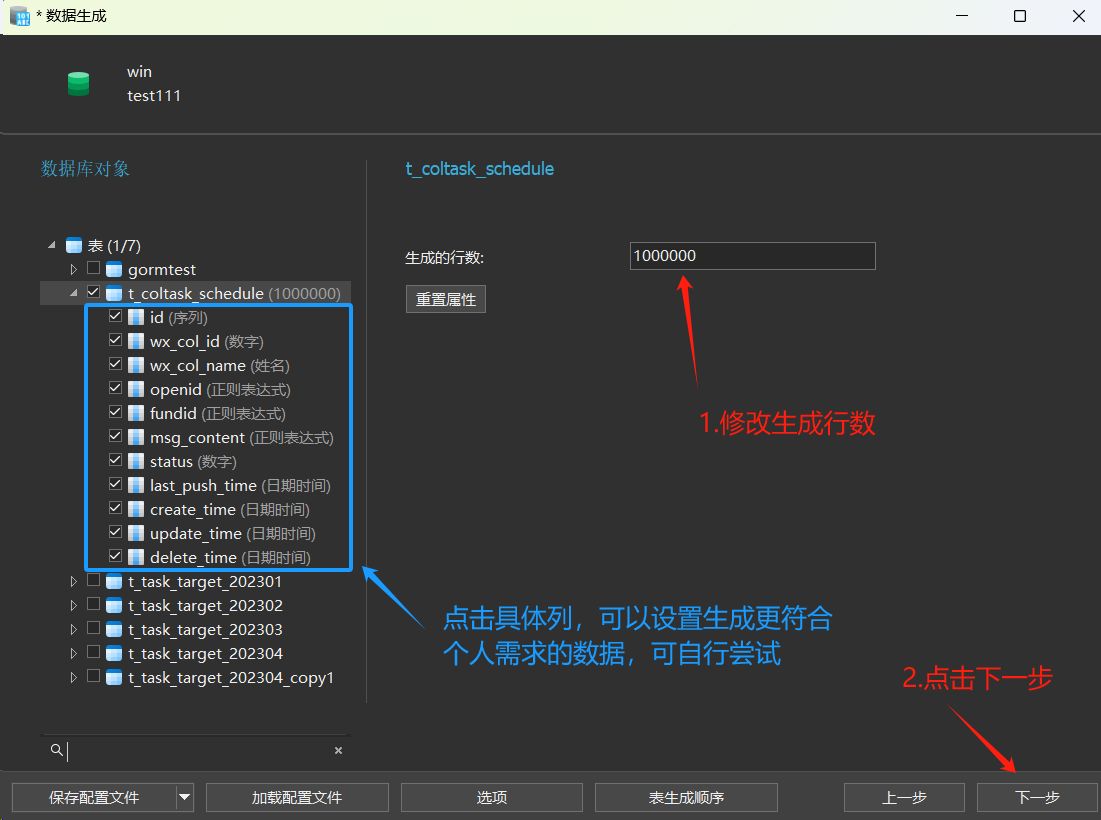
查看一下测试数据有没有正常生成吧~
索引的力量
全表扫描
我上面给的建表sql,是不包含任何索引的(除了主键id)。此时我们可以先按照如下步骤,来测试检索一条数据的效率。
-
查看执行计划可以使用
explain语句来查看没有添加索引时,mysql查询优化器的执行计划。我这里直接给出每天轮询需要执行的sql,相信在学习索引的你,理解这条sql应该没什么难度:
1explain select * from t_coltask_schedule where wx_col_id = 627 and openid = 'axgh82VQV6';上面sql中的
wx_col_id和openid两列的值,是我随机从测试数据里面捞的,你当然可以也这样做。执行之后结果如下:
如图,explain语句会返回一个表格,各列的含义如下:
- id: 查询的序列号。如果有子查询,每个子查询都有一个唯一的序列号。
- select_type: 查询的类型,可能的取值有:
- SIMPLE:简单的 SELECT 查询,不包含 UNION 或子查询等。
- PRIMARY:最外层查询。
- UNION:UNION 中的第二个或后续查询。
- SUBQUERY:子查询中的第一个 SELECT。
- DERIVED:FROM 子句中的子查询。
- UNION RESULT:UNION 的结果。
- table: 查询涉及的表名。
- partitions: 匹配的分区。
- type: 表示连接类型,常见的取值有:
- system:表只有一行(例如,对于系统表)。
- const:通过索引一次就找到了。
- eq_ref:唯一索引扫描,对于每个索引键值,表中只有一条记录匹配。
- ref:非唯一索引扫描,返回匹配某个单独值的所有行。
- range:只检索给定范围的行,使用一个索引来选择行。
- index:完全扫描整个索引。
- all:完全扫描整个表。
- possible_keys: 可能使用的索引列表,显示可能用于查询的索引。
- key: 实际使用的索引,如果为
NULL,则没有使用索引。 - key_len: 使用的索引长度。
- ref: 显示比较的列,与索引有关。
- rows: 表示估计的结果集行数,是一个估算值。
- filtered: 表示结果集行的过滤百分比。
- Extra: 包含额外的信息,例如使用了哪个索引、使用了临时表等。
具体查询时,重点关注以下几个列,可能对查询优化有帮助:
- type: 表示查询的连接类型,最好是使用索引(const、eq_ref、ref、range)而不是全表扫描(all)。
- key: 显示实际使用的索引,确保它是你期望的索引。
- rows: 估计的结果集行数,可以用于评估查询的开销。
可以看到,我们现在的查询,走了全表扫描,并且没有用到任何索引。
-
执行sql查看耗时直接执行一下sql,查看目前查询的耗时:
1 2-- SQL_NO_CACHE避免受到缓存影响 SELECT SQL_NO_CACHE * from t_coltask_schedule where wx_col_id = 627 and openid = 'axgh82VQV6';结果如下:

0.4秒+!擦擦额头的汗,还好这只是测试环境。生产上这个查询时间是不能忍受的。
好了,我想你应该有点体会了。不加索引的表格,好比一台老爷车,驾驶起来多少缺乏乐趣。
索引查询
千呼万唤始出来。前面我们聊到,不加索引的表格好比一台老爷车。为了使用最简单的方法榨干它的性能,我们可以直接装上索引这个“氮气罐”。
你可以用下面任意一种方式给表格添加索引:
-
执行sql:
1CREATE INDEX index_name ON table_name (column1, column2, ...);这里我建立如下所示的
联合索引:1CREATE INDEX idx_col_openid ON t_coltask_schedule (wx_col_id,openid);联合索引和单列索引的区别,这里不细讲。
你只要知道,当你要查询诸如 where a = “xxx” and b = “xxx” 这样的sql时,(a,b)联合索引要比a、b单列索引有效。
因为对于单列索引来说,MySQL 可能需要进行两次索引查找,分别在两个索引上查找满足条件的数据,然后合并结果。
而使用联合索引,MySQL可以直接在这个联合索引上进行查找,避免了多次索引查找和结果合并的开销,因此查询效率可能更高。
你当然也可以使用上面执行计划的方式,来对比单列索引和联合索引的执行效率。
-
图形化工具的方式建立索引:
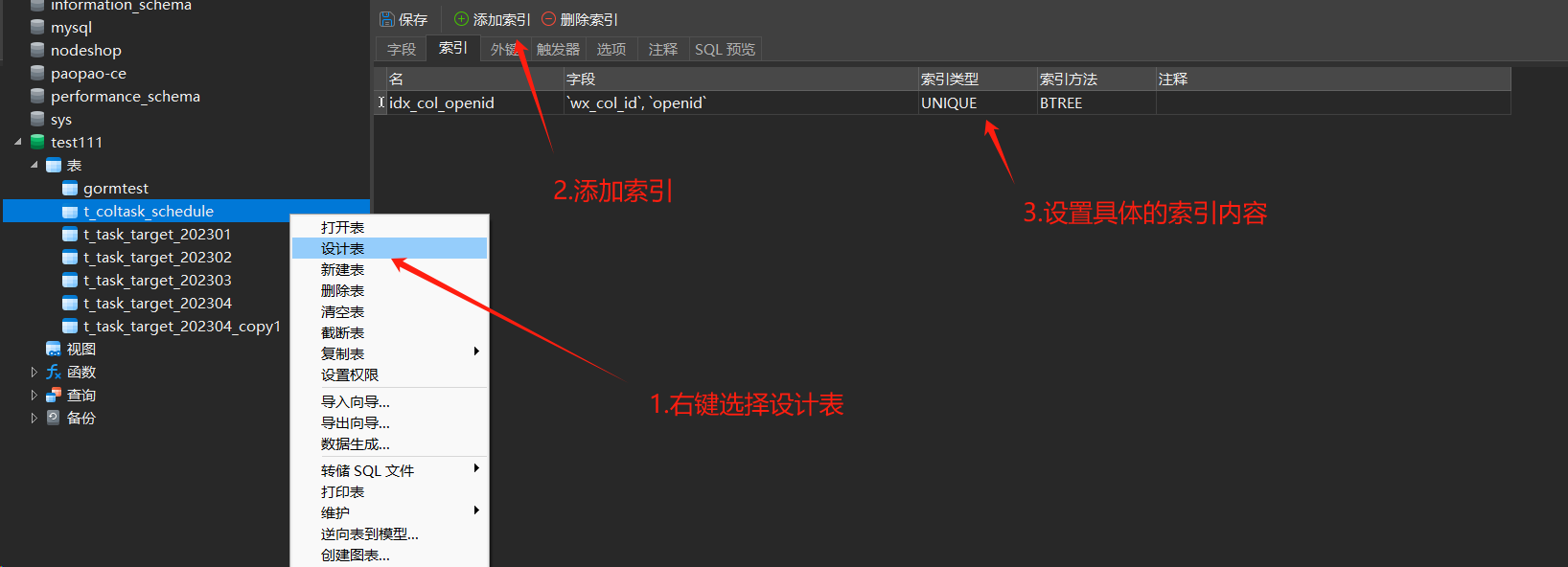
无论选择哪种方式,索引建立之后可以查看一下:
|
|

可以看到,目前我们的索引一共有两个,其中自定义的idx_col_openid包含了两列。结果中各列的含义如下:
Table:表名Non_unique:如果索引是唯一索引,则为0;如果不是唯一索引,则为1。Key_name:索引的名称Seq_in_index:索引中的列的顺序Column_name:索引中的列名Collation:列的排序规则Cardinality:索引的基数(不同值的数量)Sub_part:索引的子部分长度Packed:索引的压缩信息Null:如果列可以为NULL,则为YES;否则为NOIndex_type:索引类型(BTREE、FULLTEXT等)Comment:关于索引的注释
再次查看一下执行计划吧~
|
|
结果如图,尝试自行对比没有索引的情况分析一下:

执行查询查看耗时:

对比没有索引的情况,时间缩短了25倍!不知道你有没有像我一下,发自内心的笑了一下呢?
后记
本文的内容差不多结束了。相信你现在自己也可以回答开篇提出的问题:为什么我们需要索引呢?
不过必须提出来,索引是一个简单又强大的工具,但是也不可避免的有些限制,导致索引失效的情况。这个就作为扩展内容,留给你自己补充啦~ 当然也可以继续关注作者博客,每天会定期更新一篇噢~